The Targets file lists the microarray hybridizations and includes for each slide, the output file from an image-analysis program such as Spot, GenePix, QuantArray, ImaGene or ArrayVision. Most testing to date has been with Spot, although both GenePix and ImaGene array data have been loaded successfully into recent version of limmaGUI also. The Targets file should be in tab-delimited text format, as should be the output files from the image-analysis program. A Targets file has four essential columns (or five for ImaGene). The essential columns are a SlideNumber column, a FileName column, giving the file from image-analysis containing raw foreground and background intensities for each slide, a Cy3 column giving the RNA type reverse transcribed and labeled with Cy3 dye for that slide (e.g. Wild Type) and a Cy5 column giving the RNA type reverse transcribed and labeled with Cy5 dye for that slide. For ImaGene files, the FileName column is split into a FileNameCy3 column and a FileNameCy5. As well as the essential columns, you can have a Name column giving an alternative slide name to the default name, "Slide n", where n is the SlideNumber and you can have a Date column, listing the date of the hybridization, and as many extra columns as you like, as long as the column names are unique.
Some examples are shown below.
The ImaGene Targets file below shows the special case of the ImaGene image-processing software which gives two (tab-delimited text) output files for each slide, one for the Cy3 (Green) channel and one for the Cy5 (Red) channel. So instead of having a single FileName column, there are two file name columns: a FileNameCy3 column and a FileNameCy5 column.
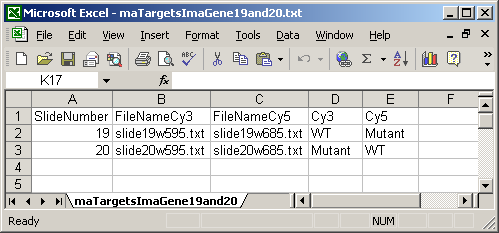
The Date column is optional and is not currently used in limmaGUI.
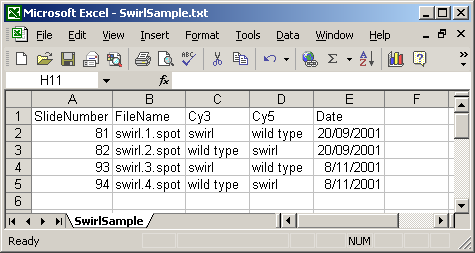
A Name column can be included, giving each array a name which can be used for plotting. In this case, a short name is used so that a box-plot of all sixteen arrays can be plotted with labels for all arrays along the horizontal axis. If no Name column is given, then a default name will be given to each slide, e.g. "Slide 1".
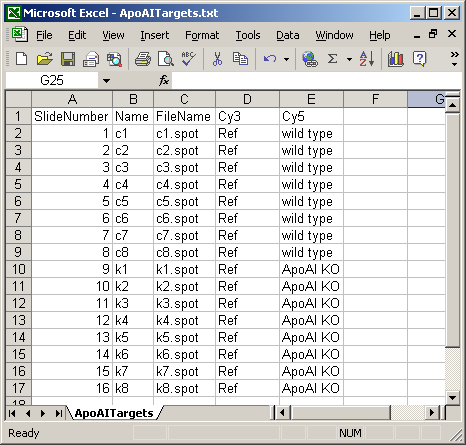
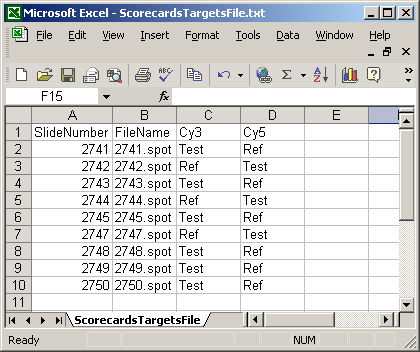
The Targets file below is from an experiment with four different RNA sources. The main Targets file is not shown. The one below is used to analyze the spiked-in scorecard controls. Spike-in controls will generally be analyzed separately from genes because the follow different rules, e.g. for genes, the log-ratio between A and B plus the log-ratio between B and C should equal the log-ratio between A and C, but for scorecard controls, all three log (red/green) ratios may be the same.
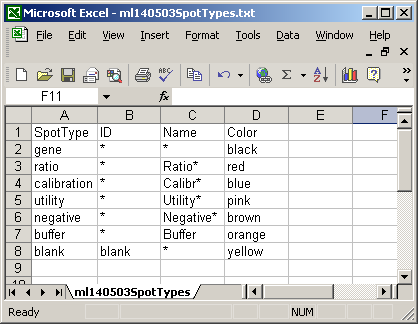
The Spot Types file (another tab-delimited text file) is optional but it is very useful in distinguishing between genes, controls and blanks when using the Color-Coded M A Plot (with legend) feature. Also, certain spot types (e.g. scorecard controls) can be excluded from a linear model fit if desired. For a given spot type, e.g. "Ratio_control_*", spot sub-types "Ratio_control_1", "Ratio_control_2" can be determined automatically to give a series of box-plots comparing the moderated t-statistics or B statistics (log odds of differential expression) between the controls, which may help in deciding which genes are truly differentially expressed, i.e. what moderated t statistic is significant.
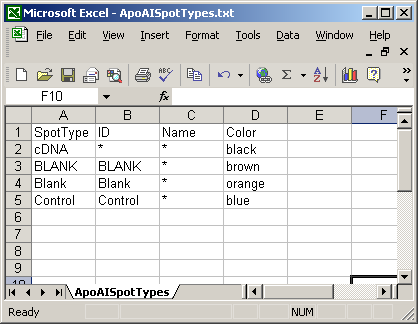
Every Spot Types file must have a SpotType column, for which each entry should be unique. It must also have an ID column, a Name column and a default Color column. The rows of the SpotTypes file should be read as a list of rules (in order) for defining spot types. The first rule usually specifies that every spot is a gene (or cDNA), then subsequent rules reclassify certain spots (controls, blanks etc.) according to what is found in the ID or Name column of the GAL file. Because these rules are applied in order, it is best to begin with spot type rules which describe large numbers of spots, followed by rules describing more and more specific spot types. For example, consider the effect of swapping the order of the two rules “1. Everything is a gene” and “2. Everything with ‘scorecard’ in the ID column is a scorecard spike-in control.”. If the more general rule (the first one) was applied after the more specific rule (the second one), it would overwrite the results of the more specific rule, so for this reason, more general rules should be in the top rows of the SpotTypes table.
The color given here is just a default color to associate with the spot type (for the Color-Coded M A Plot), and it can be modified from within limmaGUI. It is possible to give an additional column with heading 'PointSize' or 'cex' . This column gives the default size of points plotted on the Color-Coded M A Plot, according to their classified spot-type.
If you do not have a GAL file, you can either construct one, i.e. a tab-delimited text file, in the format described at http://www.axon.com/gn_GAL_Examples.html, or you can choose not to specify a GAL file, if your gene list and layout information is recording in the raw results (image-analysis) files.
Again, do not change the capitalization or spelling of the column names and do not insert extra spaces.
Here is a short spot types file.
The spot types file below defines the scorecard control spots. The asterisks are wildcards which can represent anything.
The GAL file is now optional for image-analysis file-formats which store the gene list and layout information in the raw (image-processing) results files. However, a GAL file is essential when using the (CSIRO) Spot Image Analysis format, which doesn't store any gene names or locations. The GAL file should be in tab-delimited text format. The exact format is described at http://www.axon.com/gn_GAL_Examples.html. The column names (Block, Column, Row, ID and Name) are important. Do not change their capitalization.
Make sure the image processing files are in tab-delimited text format. Do not change the capitalization of the column headings. Consult your image-analysis program manual for a description of the output files (which are input files for limmaGUI). Here's the output format for Spot: http://spot.cmis.csiro.au/spot/spotoutput.php.